Probability
Table of Contents
1 Basic conceptions
1.1 Terms
- experiment
Every probabilistic model involves an underlying process, called the experiment.
- sample space
The set of all possible outcomes is called the sample space of the experiment, denoted by \(\Omega\).
- event
A subset of the sample space, that is, a collection of possible outcomes is called an event.
- observation
The outcome of each event is called observation.
1.2 Set
A set is a collection of objects, which are the elements of the set.
- countable \(S=\{x_1, x_2, \cdots\}\)
- uncountable \(S=\{x|x\ satisfies\ P\}\)
ex: \[\{k|k/2\ is\ integer\}\] \[\{x|0\le x\le 1\}\]
- complement
The complement of a set S, with respect to the universe \(\Omega\), is the set \(\{x\in\Omega|x\notin S\}\) of all elements of \(\Omega\) that do not belong to S, and is denoted by \(S^c\). Note that \(\Omega^c = \emptyset\).
- union
\[S\cup T = \{x|x\in S\ or\ x\in T\}\] \[\bigcup_{n=1}^{\infty} = S_1\cup S_2 \cup \cdots = \{x|x\in S_n\ for\ some\ n\}\]
- intersection
\[S\cap T = \{x|x\in S\ and\ x\in T\}\] \[\bigcap_{n=1}^{\infty} = S_1\cap S_2 \cap \cdots = \{x|x\in S_n\ for\ all\ n\}\]
- difference
\[S\setminus T=S\cap T^c\] \[S\setminus T=S\setminus (S\cap T)\]
- scalar set
The set of scalars (real numbers) is denoted by \(\Re\), The two-dimensional plane is denoted by \(\Re_2\)
- algebra of set
- Commutative
\[S\cap T=T\cap S\] \[S\cup T=T\cup S\]
- Associative
\[S\cap(T\cap U)=(S\cap T)\cap U\] \[S\cup(T\cup U)=(S\cup T)\cup U\]
- Distributive
\[S\cap(T\cup U)=(S\cap T)\cup(S\cap U)\] \[S\cup(T\cap U)=(S\cup T)\cap(S\cup U)\]
- de Morgan’s laws:
\[(\bigcup_n S_n)^c=\bigcap_n S_n^c\] \[(\bigcap_n S_n)^c=\bigcup_n S_n^c\]
- others
\[(S^c)^c=S\] \[S\cap S^c=\emptyset\] \[S\cup\Omega=\Omega\] \[S\cap\Omega=S\] \[(S\setminus T)\cup T = S\cup T\]
- Commutative
1.3 Axioms
- Nonnegativity
For every event A, \[P(A) \ge 0\]
- Normalization
The probability of the entire sample space \(\omega\) is equal to 1. \[P(\Omega) = 1\]
- Additivity
If A and B are two disjoint events, then the probability of their union satisfies. \[P(A\cup B)=P(A)+P(B)\] or \(A_1, A_2, \cdots\) are disjoint events, \[P(\bigcup_{i=1}^n A_i) = \sum_{i=1}^n P(A_i)\]
1.4 Consequences
- The probability of the empty set
\[1=P(\Omega)=P(\Omega\cup\emptyset)=P(\Omega)+P(\emptyset)=1+P(\emptyset)\] \[\therefore P(\emptyset)=0\]
- Monotonicity
If \(A\subseteq B\), then \(P(A)\le P(B)\)
- Addition law
\[P(A\cup B)=P(A)+P(B)-P(A\cap B)\]
- others
- \(P(A\cup B)\le P(A)+P(B)\) (addition law & axioms 1)
- \(P(A\cup B\cup C) = P(A) + P(A^c\cap B) + P(A^c\cap B^c\cap C)\) (axioms 3)
- if \(P(A\cap B)\) equals to 0, then A and B are mutually exclusive
1.5 Random Variable
random variable is a variable that can takes on a set of values(a random value)
1.6 Discrete Variable
discrete: if a variable is discrete, that means it can only take exact values.
1.7 Continuous Variable
1.8 Expectation
1.9 Variance
\[\begin{align*} Var[X] & = E[(X-E[X])^2] \\ & = E[X^2-2E[X] X + E[X]^2] \\ & = E[X^2]-2E[X]\cdot E[X] + E[X]^2 \\ & = E[X^2]-E[X]^2 \end{align*}\]
1.10 Standard Deviation
\[\sigma=\sqrt{Var[X]}\]
1.11 Moment
The \(n_{th}\) moment of a random variable is the expected value of its \(n_{th}\) power \[\mu_X(n)=E[X^n]\]
1.12 Central Moment
The \(n_{th}\) central moment of a random variable X is the expected value of the \(n_{th}\) power of the deviation of X from its expected value. \[\bar\mu_X(n)=E[(X-E[X])^n]\]
- Variance: 2nd central moment
- Skewness: 3th central moment
- Kurtosis: 4th central moment
2 Conditional probabilities
2.1 Conceptions
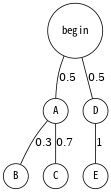
2.2 Axioms
2.3 Consequences
- Multiplication Rule
\[P(\cap_{i=1}^{n}A_i)=P(A_1)P(A_2|A_1)P(A_3|A_1\cap A_2)\cdots P(A_n|\cap_{i=1}^{n-1}A_i)=\prod_{i=1}^n P(A_n|\cap_{i=1}^{n-1}A_i)\]
- proof \[P(\cap_{i=1}^n A_i)=P(A_1)\frac{P(A_1\cap A_2)}{P(A_1)}\cdots\frac{P(\cap_{i=1}^n A_i)}{P(\cap_{i=1}^{n-1} A_i)}\] \[=P(A_1)P(A_2|A_1)\cdots P(A_n|\cap_{i=1}^{n-1} A_i)\]
2.4 Total Probability Theorem
Let \(A_1, A_2,\cdots, A_n\) be disjoint events that form a partition of the sample space, then for any event B: \[P(B)=P(A_1\cap B)+\cdots+P(A_n\cap B)\] \[=P(A_1)P(B|A_1)+\cdots+P(A_n)P(B|A_n)\]
2.5 Bayes’ Rule
- Useful for finding reverse conditional probabilities.
Let \(A_1, A_2,\cdots, A_n\) be disjoint events that form a partition of the sample space, then for any event B: \[P(A_i\cap B)=P(A_i|B)P(B)=P(A_i)P(B|A_i)\] \[P(A_i|B)=\frac{P(A_i)P(B|A_i)}{P(B)}\]
- depends on total probability theorem, we have:
\[P(A_i|B)=\frac{P(A_i)P(B|A_i)}{P(A_1)P(B|A_1)+\cdots+P(A_n)P(B|A_n)}\]
2.6 Independence
if A and B are independent events. \[P(A|B)=P(A)\] is equivalent to \[P(A\cap B)=P(A)P(B)\]
- If \(A\) and \(B\) are independent, so are \(A\) and \(B^c\)
2.7 Conditional Independence
Two events A and B are said to be conditionally independent \[P(A\cap B|C)=P(A|C)P(B|C)\] is equivalent to(hint: Bayes' rule) \[P(A|B\cap C)=P(A|C)\]
3 Random Variables
- difinition: A random variable is a real-valued function of the outcome of the experiment
- A function of a random variable defines another random variable
3.1 Discrete RV
- A (discrete) random variable has an associated probability mass function(PMF)
3.2 Continuous RV
- PDF
\[\begin{align*} PDF_X(x) & =\lim_{\varDelta x\to 0}\frac{P(x\le X \le x+\varDelta x)}{\varDelta x}\\ & =\lim_{\varDelta x\to 0}\frac{CDF_X(x+\varDelta x)-CDF_X(x)}{\varDelta x}\\ & = CDF^\prime_X(x) \end{align*}\]
\[\begin{align*} P_X(a < x \le b) & = CDF_X(b)-CDF_X(a)\\ & = \int_{-\infty}^b PDF_X(x)\mathrm{d}x - \int_{-\infty}^a PDF_X(x)\mathrm{d}x\\ & = \int_a^b PDF_X(x)\mathrm{d}x \end{align*}\]
- \(\int_{-\infty}^{\infty}PDF_X(x)\mathrm{d}x = 1\)
- \(PDF_X(x)\ge 0\) for all \(x\)
- If \(\varDelta x\) is very small, then \(P(x\le X \le x+\varDelta x) \approx PDF_X(x)\cdot \varDelta x\)
- CDF
\[CDF_X(x)=P(X\le x)=\int_{-\infty}^x PDF_X(u)\mathrm{d}u\]
4 Counting
- Permutations of n objects: \(n!\)
- k-permutations of n objects: \(\frac{n!}{(n-k)!}\)
- Combinations of k out of n objects: \({n\choose k}=\frac{n!}{k!(n-k)!}\)
Partitions of \(n\) objects into \(r\) groups with i th group having \(n_i\) objests:
\[{n \choose n_1,n_2,\cdots,n_r} = \frac{n!}{n_1!n_2!\cdots n_r!}\] this is called multinomial coefficient
4.1 n balls into m boxes
- ball same, box same -> enum
- ball same, box diff -> partition
- box not null: \({n-1 \choose k-1}\)
- box nullable: \({n+k-1 \choose k-1}\)
5 Linear Transforms
Linear transforms are when a variable X is transformed into aX + b, where a and b are constants. The probabilities of each Y should be the same as X \[E(aX+b)=aE[X]+b\] \[Var(aX+b)=a^2Var[X]\]
5.1 Independent observations
\[E(X_1+X_2+...X_n) = nE[X]\] \[Var(X_1+X_2+...X_n) = nVar[X]\]
5.2 Independent Variables
X and Y are independent random variables \[E(X+Y)=E[X]+E[Y]\] \[E(X-Y)=E[X]-E[Y]\] \[Var(X+Y)=Var[X]+Var(Y)\] \[Var(X-Y)=Var[X]+Var(Y)\]
- linear transforms \[E(aX+bY)=aE[X]+bE[Y]\] \[E(aX-bY)=aE[X]-bE[Y]\] \[Var(aX+bY)=a2Var[X]+b2Var(Y)\] \[Var(aX-bY)=a2Var[X]-b2Var(Y)\]
6 Discrete distributions
6.1 Binomial distribution
- You’re running a series of independent trials.
- There can be either a success or failure for each trial, and the probability of success is the same for each trial.
- There are a finite number of trials.
- The main thing you’re interested in is the number of successes in the \(n\) independent trials.
Let:
- \(X\) be the number of successful outcomes out of \(n\) trials
- \(p\) be the probability of success in a trial
\[X\sim B(n, p)\]
6.2 Geometric distribution
- You run a series of independent trials.
- There can be either a success or failure for each trial, and the probability of success is the same for each trial.
- The main thing you’re interested in is how many trials are needed in order to get the first successful outcome.
Let:
- \(X\) be the number of trials needed to get the first successful outcome
- \(p\) be the probability of success in a trial
\[X\sim Geo(p)\]
6.3 Pascal distribution
aslo known as Negative Binomial Distribution
- You run a series of independent trials.
- There can be either a success or failure for each trial, and the probability of success is the same for each trial.
- The main thing you’re interested in is how many trials are needed in order to get the \(k\) successful outcomes.
Let:
- \(X\) be the number of trials needed to get the \(k\) successful outcomes
- \(p\) be the probability of success in a trial
\[X\sim Pascal(k, p)\]
- PMF
\[PMF_X(x)=\begin{cases} {x-1 \choose k-1}(1-p)^{x-k}p^k, & x\ge k\\ 0, & otherwise\\ \end{cases}\]
- E[X]
\[E[X]=\frac{k}{p}\]
- Var[X]
\[Var[X]=\frac{k(1-p)}{p^2}\]
- CDF
\[CDF_X(x)=\begin{cases} I_p(k, \lfloor x \rfloor - k + 1), & x\ge k\\ 0, & otherwise\\ \end{cases}\] \(I_z(a,b)\) is the regularized incomplete beta function
6.4 Poisson distribution
- Individual events occur at random and independently in a given interval.
- You know the mean number of occurrences in the interval or the rate of occurrences, and it’s finite.
- The purpose is to know the number of occurrences in another particular interval.
Let:
- \(X\) be the number of occurrences in a particular interval \(T\)
- \(\lambda\) be the rate of occurrences, should be \(uT\), \(u\) is the frequency of occurrences
\[X\sim Po(\lambda)\]
- PMF
\[PMF_X(x)=\frac{e^{-\lambda}\lambda^{x}}{x!}\]
- E[X]
\[E[X]=\lambda\]
- Var[X]
\[Var[X]=\lambda\]
- CDF
\[CDF_X(x)= \begin{cases} -\lambda^e\sum_{n=-\infty}^{\lfloor x \rfloor}e^{-\lambda}\cdot \frac{\lambda^n}{n!}, & \mbox{if }x\ge 1 \\ 0, & \mbox{otherwise} \\ \end{cases}\]
- linear transforms
If \(X\sim Po(\lambda_x)\) and \(Y\sim Po(\lambda_y)\), and \(X\) and \(Y\) are independent, \[X+Y\sim Po(\lambda_x + \lambda_y)\]
- simplify the special Binomial distribution case
If \(X\sim B(n, p)\) where \(n\) is large and \(p\) is small, you can approximate it with \(X \sim Po(np)\).
7 Continuous distributions
7.1 Relationship between PDF & CDF
\[\frac{dy}{dx}CDF(x)=\int PDF(x)dx\]
7.2 Exponential distribution
How long do we need to wait before a customer enters our shop? How long will it take before a call center receives the next phone call? All these questions concern the time we need to wait before a given event occurs. If this waiting time is unknown, it is often appropriate to think of it as a random variable having an exponential. \[X\sim Exponential(\lambda)\]
- most commonly used to model waiting times
- \(\lambda\) is called rate parameter
7.3 Erlang distribution
Given a Poisson distribution with a rate of change \(\lambda\), We use Erlang distribution to calculate the waiting times until the \(n\) th Poisson event occurs.
\[X\sim Erlang(n, \lambda)\]
- PDF
\[PDF_X(x)=\begin{cases} \frac{1}{(n-1)!}\lambda^n x^{n-1} e^{-\lambda x}, & x\ge 0\\ 0, & otherwise \end{cases}\]
- E[X]
\[E[X]=\frac{n}{\lambda}\]
- Var[X]
\[Var[X]=\frac{n}{\lambda^2}\]
- CDF
\[CDF_X(x)=\begin{cases} 1-\sum_{k=0}^{n-1}\frac{(\lambda x)^k}{k!}e^{-\lambda x}, & x\ge 0\\ 0, & otherwise \end{cases}\]
7.4 Normal distribution
\[X\sim N(\mu, \sigma^2)\] or \[X\sim Gaussian(\mu, \sigma)\]
- PDF
\[PDF_X(x)=\frac{1}{\sigma\sqrt{2\pi}}\cdot e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
- CDF
\[CDF_X(x) = \int_{-\infty}^{x}PDF_X(x)dx=\frac{1}{\sigma\sqrt{2\pi}}\int_{-\infty}^{x}e^{-\frac{(x-\mu)^2}{2\sigma^2}}dx\]
- Use z-table
- approximate Binomial distribution
if \(X\sim B(n, p)\) and \(np>15\) and \(nq>5\) , use \(X\sim N(np, npq)\) to approximate it.
- need to apply a continuity correction (round to discrete value), eg [5.5, 6.5) round to 6
- approximate Poisson distribution
if \(X\sim Po(\lambda)\) and \(\lambda>15\), use \(X\sim N(\lambda, \lambda)\) to approximate it.
- need to apply a continuity correction (round to discrete value)
8 Binomial Theorem
\[(x+y)^n = \sum_{k=0}^{n} \dbinom{n}{k}x^{n-k}y^{k}\]
9 Function of Random Variable
Let \(Y=g(X)\)
9.1 Discrete
\[PMF_Y(y)=\sum_{\forall x|g(x)=y}PMF_X(x)\]
10 Conditional probability distributions
10.1 Discrete
10.2 Continuous
10.3 Memoryless
\[PMF_{X|Y}(x|y) = PMF_{X}{x}\] e.g.
- Geometric distribution
- Exponential distribution
11 Joint probability distributions
11.1 PMF/PDF
- Discrete
\[PMF_{X,Y}(x, y) = P(X=x\ and\ Y=y)\]
- \(0\le PMF_{X,Y}(x, y) \le 1\)
- \(\sum_{x=-\infty}^{\infty}\sum_{y=-\infty}^{\infty}PMF_{X,Y}(x, y)=1\)
- if \(X,Y\) are independent, \(PMF_{X,Y}(x, y)=PMF_X(x)PMF_Y(y)\)
- Continuous
\[PDF_{X,Y}(x, y) = \frac{d CDF_{X,Y}(x, y)}{dx}\frac{d CDF_{X,Y}(x, y)}{dy}\] \[CDF_{X,Y}(x, y) = \int_{-\infty}^{x}\int_{-\infty}^{y}PDF_{X,Y}(u, v)dvdu\]
11.2 CDF
\[CDF_{X,Y}(x, y) = P(X\le x\ and\ Y\le y)\]
- \(CDF_{X,Y}(x, \infty) = CDF_X(x)\)
11.3 E[h(X, Y)]
- Discrete
\[E[h(X, Y)]=\sum_{x=-\infty}^{\infty}\sum_{y=-\infty}^{\infty}h(x, y)\cdot PMF_{X,Y}(x, y)\]
- Continuous
\[E[h(X, Y)]=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}h(x, y)\cdot PDF_{X,Y}(x, y)dxdy\]
- Transformation
- \(E[\alpha h_1(X, Y)+\beta h_2(X, Y)=\alpha E[h_1(X, Y)]+\beta E[h_2(X, Y)]\)
- If \(X, Y\) are independent, \(E[g(X)h(Y)]=E[g(X)]\cdot E[h(Y)]\)
11.4 Var(X+Y)
\[\begin{align*} Var(X+Y) & = E[(X+Y-E[X+Y])^2] \\ & = E[(X-\mu_X+Y-\mu_Y)^2] \\ & = E[(X-\mu_X)^2 + (Y-\mu_Y)^2 + 2(X-\mu_X)(Y-\mu_Y)] \\ & = Var(X) + Var(Y) + 2Cov(X, Y) \end{align*}\]